如何选择适合深度学习的GPU(收藏必备)
2024-10-25 19:55:42
工欲善其事,必先利其器!深度学习作为计算密集型领域,显卡的选择在很大程度上直接影响到使用体验,因此,选择合适的GPU是一个关键决策。那么在2022年,如何选择适合深度学习的GPU呢?
随着人工智能和深度学习的迅猛发展,GPU(图形处理单元)作为核心计算设备的重要性日益凸显。无论是研究人员、数据科学家还是开发者,选择GPU时都需综合考量多种因素,以确保高效、稳定地完成深度学习模型的训练和推理。以下是一份关于如何选择深度学习GPU的详细指南。

一、CPU与GPU性能选择
在不同深度学习架构下,GPU选择的优先级各有不同,以下是一些通用推荐:
- 卷积网络和Transformer架构:Tensor Cores > FLOPs > 内存带宽 > 16位计算能力
- 递归网络:内存带宽 > 16位计算能力 > Tensor Cores > FLOPs
二、如何选择GPU?
由于NVIDIA的CUDA标准库支持广泛,使得在其平台上构建深度学习库变得十分便捷。此外,NVIDIA的社区支持也相对完善。然而,NVIDIA的政策限制仅Tesla GPU可在数据中心使用CUDA,而GTX或RTX系列则不允许,且Tesla的价格高出其他型号近十倍。
AMD虽然具备16位计算能力,但相较NVIDIA的Tensor Cores仍存在一定差距,且支持力度较弱。Google的TPU因复杂的并行架构在多节点下效率优越,尤其适合卷积神经网络的训练,在成本效益上表现出色。
三、GPU并行加速
卷积网络和循环网络在并行计算中表现优异,单机或4块GPU配置下的运行效果较好;TensorFlow和PyTorch都支持并行递归计算。然而,Transformer架构的全连接网络在数据并行性方面较弱,通常需更高级的算法加速。建议先在单个GPU上进行测试,以便确定是否需要多GPU并行。
在单一GPU上已经能胜任多数深度学习任务的情况下,多GPU的并行性(如PCIe通道数)重要性并不高。
四、性能评测
1)Tim Dettmers的成本效益评测显示,RTX 2060的性价比超过Tesla V100的5倍以上。使用16位Tensor Cores进行计算较仅增加更多Cores更具成本效益。
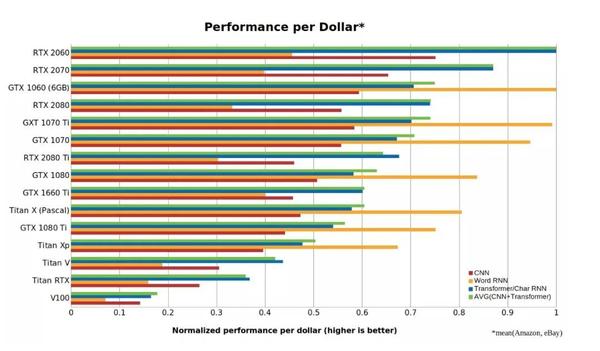
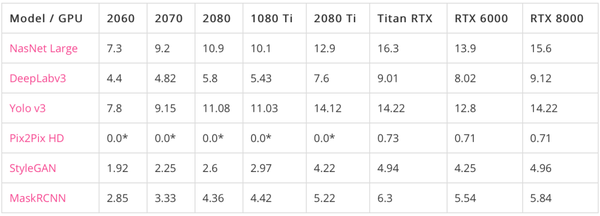
2)Lambda的评测也显示了RTX系列在深度学习中的优越性,RTX 8000在图像处理吞吐量上尤为出色,适合大规模图像模型训练任务。
3)国内用户普遍使用Google Colab,免费版的K80性能较低,适合跑简单模型。付费版提供T4或P100,月费为10美元。百度AI Studio则提供V100算力,对使用PaddlePaddle的用户较为友好。
五、推荐配置
- 最佳选择:RTX 2070,性价比高,适合大多数深度学习任务。
- 避免使用:Tesla、Quadro及Founders Edition系列,价格过高而性价比偏低。
- 高性价比:RTX 2060、GTX 1060(6GB)适合预算有限的用户。
- 适合大型任务:RTX 2080 Ti适合深度学习专业研究者,预算在8-9k左右。
- SOTA模型需求:Quadro RTX 8000(48GB)适合预算充足的用户,性能卓越。
六、云桌面与深度学习的结合
云桌面技术已逐渐应用于深度学习,结合虚拟化技术,将硬件资源集中在云端供用户访问,提升计算能力和灵活性。云桌面广泛应用于教育、企业协作、视觉设计和游戏等场景,具有以下优势:
- 用户无需购置高配硬件即可享受云端计算,适合异地协作。
- 强大的数据安全保障,节省IT成本。
- 高资源利用率,无需重复投资硬件。
深度学习可利用云桌面提供的GPU算力执行高计算量任务,提高模型训练效率。
七、云桌面面临的挑战
- 性能损耗:高并发情况下,云桌面依赖网络和虚拟技术,性能受限。
- 数据安全:数据在云端存储,需加强安全保障。
- 高可用性:需保证云桌面软硬件及网络传输的高可用性。
随着技术进步,云桌面与深度学习结合更加紧密。例如,NVIDIA的深度学习解决方案支持多平台,能够从训练到推理全过程应用。未来,云桌面将逐渐从单纯的桌面工具转变为集成桌面、数据、协作等多功能生产力工具,满足未来企业需求。
目前,深度学习与云电脑的结合备受关注。对于硬件资源不足、电脑性能受限的用户,推荐试用FinovyCloud云桌面!
FinovyCloud云桌面新用户现可免费体验,支持游戏、建模、剪辑、深度学习和AI大模型训练等多场景应用!新用户注册并联系在线客服即可领取100元代金券,畅享高配云桌面体验!

